ここでは番外編として、細胞システムの数理モデルとロバストネス解析について今の時点で思うことを書いてみたい。第2部:ロバストネス解析としてのgTOWー発展と終わりでも書いたが、守屋研での(?)ロバストネス解析としてのgTOWは一端終わった。理由はいろいろ書いたが、ウケなかったからだ。ウケなかったというのは、つまり研究費が取れなかったと言うこと。ただ、結局のところ、守屋自身がその研究をやりたいという情熱に満ちていなかった。皮肉なことに、研究費が取れなくてもやるという情熱がなければ、研究費は取れない。
それでは、ロバストネス解析が終わって10年たった今の状況はどうなっているのだろうか? それを少し考えてみたい。守屋自身は、数理モデリングやロバストネス解析から撤退したので、実はその後の発展をほとんどフォローしていない事を断っておく。だから、ちゃんとフォローしていないなりの守屋の感想で、いろいろ間違っているかも知れない。だが、こういう風に書き出すことが、合ってるか間違ってるかを議論する遡上に挙げることになる。だから、無知を承知で書いてみることにする。
細胞周期の数理モデル
まず、細胞周期の数理モデル、守屋が愛した(?)Chen 2004モデルである(Chen MBoC 2004)。第1部:ロバストネス解析としてのgTOWーはじまりから完成まででも書いたが、このモデルは守屋がちょうど「システムバイオロジー」を始めたときに発表されて、これを写経するかのごとく分解することで、数理モデリングを学んだ。自分のブログにも、CellDesignerでこのモデルを再構築するエントリーシリーズを投稿している。この時作ったモデル図はパネルにして貼ってもいる。守屋はとてもカッコいいと思っているのだが、誰にも響いていないようだ。
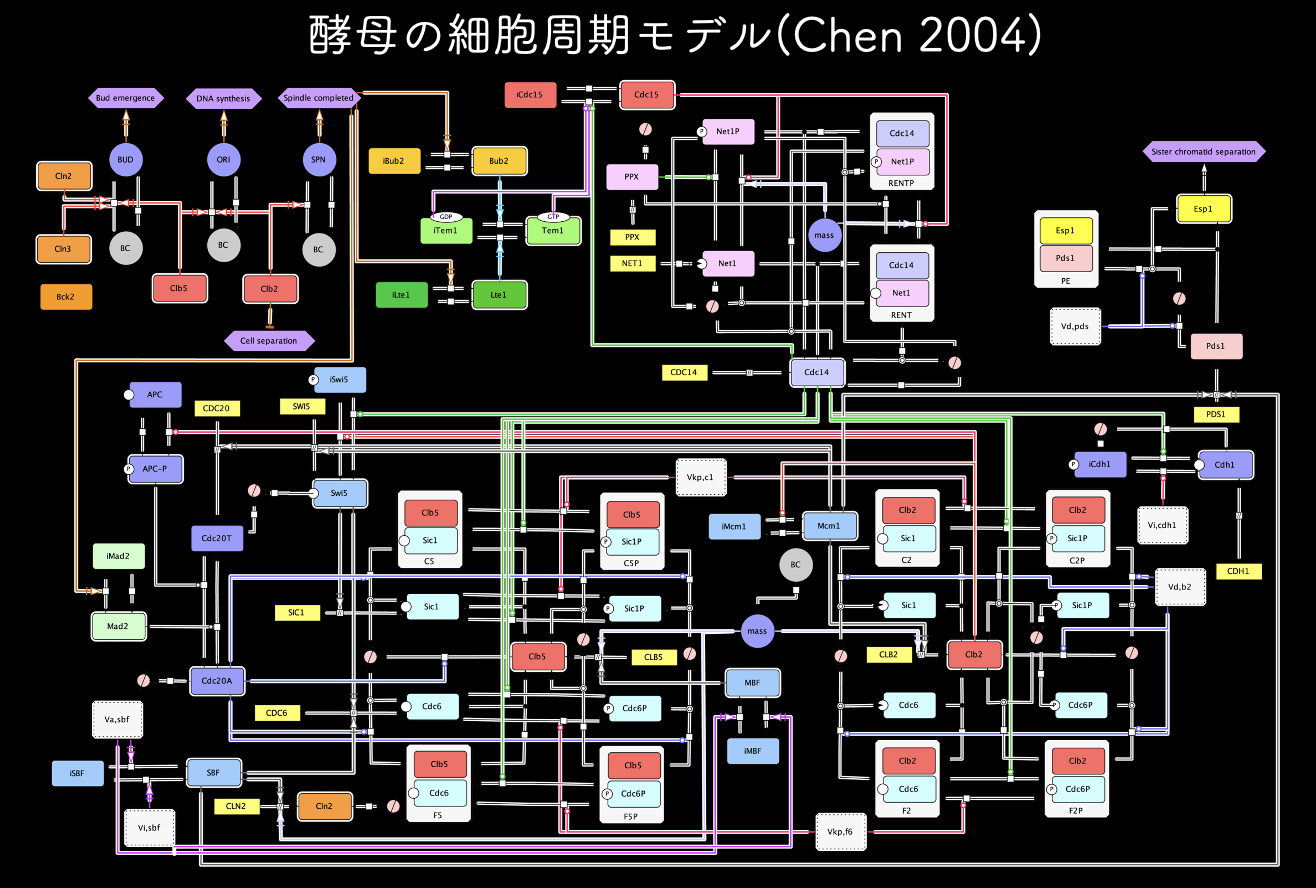
この筆頭著者のChen誌は、実際にはガチガチの数理モデラーではなく、Tyson研の技術職員のようなポジションだったそうだ。で、こういうモデルは結局作者にしかいじれないアートのようなものになり、これ以上拡張できない。実際、若干の改良版がこのあとTyson研から出るのだが、このモデルのエレガントさに勝てていない。また、John Tyson氏の弟子にあたるBela Novak氏はモデラーとしてのセンスは抜群だが、そうであるが為に、モデルの複雑化の方向には進んでいない。
AIの登場により、システムバイオロジーモデルの役割は失われた?
折り悪く(?)、Deep-Learning(DL)、Large Language Model(LLM)と続く機械学習のAIがブレイクする。生命現象の振る舞いを解釈したり予測したりしたいというときの第一選択が、ややこしい数理モデルではなくなった。数理モデルでは、本当にゴチャゴチャした細胞の中の分子の振る舞いを、なんとかして数理化しその解を計算機で解かなければならない。数理化も計算も大変すぎる。動作原理が分からなくてもデータを大量にぶち込んだらすごい予測精度で答えを返してくれるAIの方がよっぽど目的への近道だ。「生命システムの動作原理を知りたいという」知的欲求を満たすのであれば、複雑なシステムバイオロジーモデルは必要ない。知りたい現象に特化したシンプルなモデルで十分であり、またシンプルでなければ人間には理解できないからだ。守屋のロバストネス解析にしても、Chenのモデルくらいの複雑さがちょうど良い。複雑怪奇なモデルのロバストネス発揮の原理は、結局分かったようで分からない。
つまり、複雑な方向に進む「システムバイオロジー」っぽいモデルは、深化の必要性がなくなってしまった。なるほどこれじゃあ研究費も取れないはずだ。じゃあこれからどうなるのか? もう終わったのか? これは守屋自身もまだ答えがない。この手のシミュレーション自体は面白いし、生物の作りを理解するためには1度は体を通しておいた方が良いものだとは思っている。やってみたい人にはやり方を教えるので聞いて欲しい。
ロバストネス解析の概念を表した仕事
もう一つ書いておきたかったこと。それはKerenらの「Massively Parallel Interrogation of the Effects of Gene Expression Levels on Fitness」という仕事(Keren Cell 2016)である。これ、Cellというとても権威のある雑誌に掲載されたもので、非常に簡単にいうと遺伝子発現量を変えたときに、増殖速度にどのような影響を与えるかを調べた研究である。
具体的には、標的の遺伝子1つずつについてプロモーターの強度を500倍のレンジで変えてた株を130種類ずつ作り、それらを混ぜてプール培養してNGS解析して適応度を測ったというもの。なかなか大変そうな仕事、だから標的の遺伝子は80種類くらいしかない。
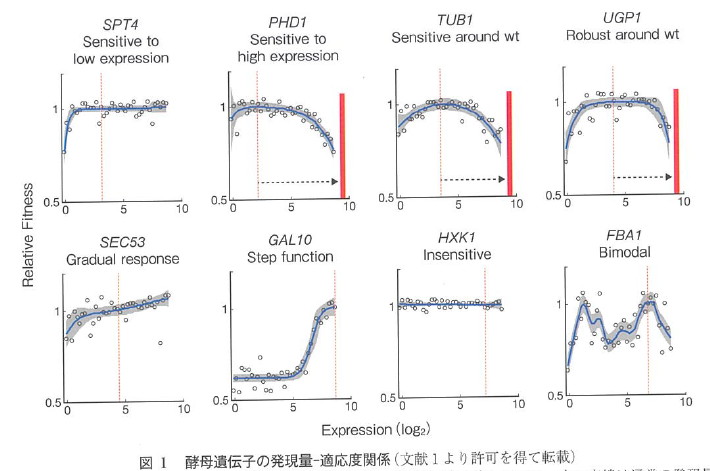
それで得られるものが、発現量ー適応度関係というグラフ(上図)。このグラフを見た瞬間、「あ、これって守屋がロバストネス解析で示したかったことじゃん!」と思った。それと同時に、「このデータはgTOWを説明するのにすごく良いぞ」と思った。つまり、gTOWでは適応度が下がる一番高いときの発現量を体系的に調べることができる。図の赤い線だ。「こういうことをやりたいんです」というプレゼンにすごく使えるフィギアとなった。だから上記の生体と科学の2018年の解説でも使っている。
これから再び「ロバストネス解析」が始まるのかも知れない
このエントリーで何が言いたいかというと、やっと時代が追いついたかということ。守屋は2006年にすでにそのコンセプトの実験をやってたんだぞ、と。ただ、残念ながら引用もされていないし、みんなその価値に気づいてくれなかった。守屋の実力が足りないんです。そうなんです。ではあるが、守屋自身もこの研究によって気づかされたことも多く、最近よく使っている発現量を決める2つの進化原理のモデル図(下図)も、この研究にインスパイアされたものである。
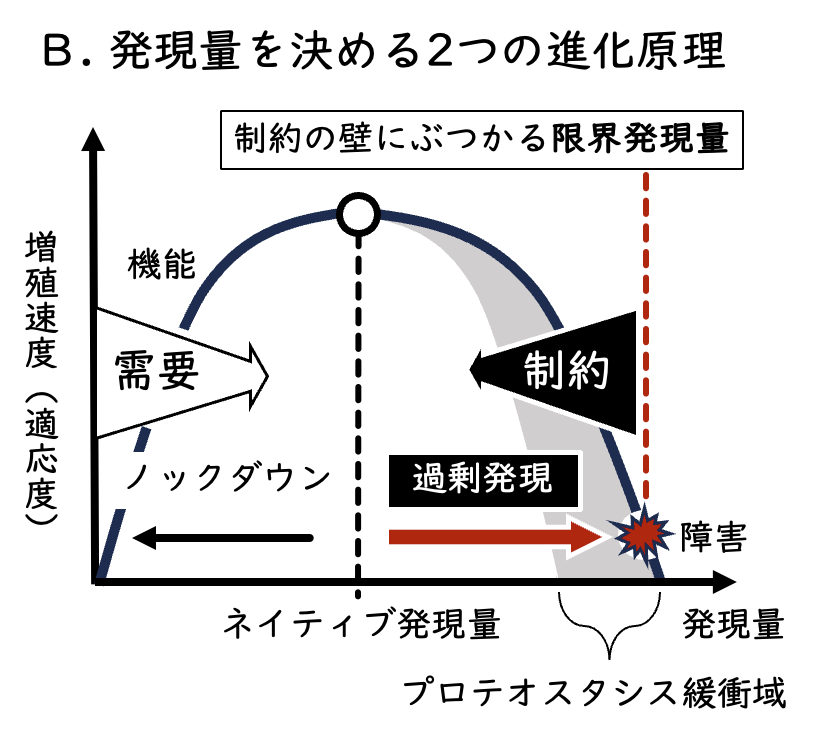
この図に表されているような、タンパク質発現量を決める制約のメカニズムが、現在の守屋研の「タンパク質の暗黒面プロジェクト」の基本理念である。つまりは、やっぱりロバストネス解析から繋がってると言うことで、だから、もう一度ロバストネスという言葉を使い始めようと思い始めている、ということなのだ。